In healthcare, data quality and security play a crucial role. That’s why at LOGEX, we’ve developed our own platform for managing and tracking data, enabling secure and transparent handling of sensitive information. How does the system work and how do we ensure its reliability? Read on to find out.
In LOGEX, we enable our customers — primarily hospitals and research institutions — to exchange data among each other. This ranges from traditional financial analytics to clinical data — for example, cancer treatment which fuels further research.
In our article, "Building Trust in Healthcare Data with the Nightingale Data Platform," we explore how we unify data exchange and track its full lifecycle through a powerful data lineage solution designed specifically for the healthcare industry.
Objectives of Data Lineage
We are building a scalable and interoperable data platform, which enables users to perform CRUD operations on data — such as batch uploads, in-house tools, 3rd party application uploads, or modifications of existing records. In order to be able to track data and its changes over time we had to create Data Lineage solution that would be able to answer following questions.
Where did the data come from?
Data we handle comes from hospitals, but since the data describes particular patients, the General Data Protection Regulation (GDPR) protects it. This means, that when a single patient decides that they want their data deleted, for whatever reason, we are able to delete all their data across the data platform. But this isn't the only case when we need to delete or modify the existing data. Sometimes hospitals can request a deletion or change of something they already sent to us, for numerous reasons. Which creates an interesting problem our data lineage solution must solve.
How did the data appear in a table?
Our Data Lineage solution will be able to point out exactly where any row of data came from, which tables were affected by it, and where it appeared, either upstream or downstream. This becomes more complex if we also consider features such as sums, counts, ML features etc. In order to ensure the data platforms pipelines are robust, we work hand in hand with our customers, to make sure the data is of the highest quality. In the development stages of data products we iteratively check and debug our data. Unexpected changes happen, business logic alters and that affects the output of our pipelines. In order to add additional context to data loading process, we also provide metadata of the loading process, such as the data loading type, primary keys etc. This additional context provides our customers transparency of changes in our data and also makes debugging of the data much faster.
Technical Solution
To debug processes effectively and reconstruct the correct state of data at any point in time—without reprocessing the entire history—we rely on metadata such as the type of loading process (e.g., incremental vs. full), primary keys, deduplication rules (e.g., which record takes precedence) and state of the data at that point.
Cost effectiveness
By this design we enable our customer support team to (un)delete data. Since batches are processed one after the other, they can rely on data from the past, or affect the data in the future. So when we are asked to delete data from an old batch, and we have already processed several batches since then, we basically have to choices:
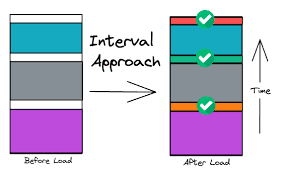
Point in time recovery
Accounting for this scenario, we are able to store data loading information during the runtime of our ETLs. This allows us to have the metadata needed to reconstruct state of data at any point in time.
Reusable components
From a technical standpoint, we've designed the data lineage as a shared library, providing our colleagues with a standardized approach to documenting and understanding data transformations. This foundation supports a robust data lineage solution — making it easier to trace where data comes from, how it changes, and why it looks the way it does.
Building a powerful data tooling
By developing a modular and reusable solution for tracking data lineage across our platform, we've established a standardized and holistic approach to monitoring data changes. This not only lifts the burden of lineage tracking from individual developers, but also empowers both our engineering teams and customer office with powerful tools. By embedding these capabilities into the core of our platform, we're helping healthcare institutions not just move data — but trust it. A big thank-you goes to Václav Pazderka and Filip Vašš, who wrote the article and helped us bring it to life.




